|
|
Все выгружаемые данные сжимаются функцией gzencode($str, 9), поэтому приходится эти данные накапливать – ведь если сжимать каждую строку таблицы, сжатие будет неэффективным, несмотря на указанный нами параметр "максимальное сжатие". |

| Главная |  | Товары в газете | | Стоимость рекламы | | База данных | | Страницы | | Веб-агентство |
Копирование сайтов, синхронизация (Mysql, PHP)
Копировать информацию с сайта можно с разными целями: 1) резервное копирование (backup), 2) перенос сайта на новый хостинг, 3) синхронизация сайтов (или баз данных), обновление актуальной информации. В статье («Хостинг в Иркутске») мы говорили о копировании файлов (серверных скриптов, картинок и др.) – там мы исходили из небольшого объёма файловой информации (существенные файлы четырёх наших сайтов занимают 1.5Мб), так что предложенный метод можно использовать для всех трёх случаев. Мы используем, и пока не планируем что-то менять (скачивать 1.5Мб для трафика не тяжело хоть каждый день, хоть чаще).
С базами данных так просто не получится. Нужны разные скрипты для резервного копирования и для синхронизации. И при резервном копировании, так же как и при синхронизации, необходимо оптимизировать процесс, чтобы не скачивать лишнее.
Резервное копирование
Логика оптимизации не очень сложна: не надо копировать всё. Всегда есть информация, которая не меняется от рождения сайта до его смерти. Можно определить и другие временные рамки для «статичной» информации: например, от изменения к изменению таблиц (не изменяемых посетителями сайта) программистом – ведь существенно изменяют таблицы сначала локально, а потом их копируют на хостинг, следовательно, резервная копия уже у нас есть.
К «нескачиваемой» информации можно добавить «секретную» информацию (необходимую для данного хостинга, но опасную в других местах). В общем, нужно произвольное решение, перечень таблиц, которые не будут скачиваться при синхронизации и резервном копировании. Эти перечни могут быть разными, но у нас пока список для всех способов копирования общий; формируется он простым способом, в самой структуре БД: таблицы, которые не надо скачивать, начинаются с префикса private_. Например, в одной БД у нас есть таблица с англо-русским словарём Мюллера. Зачем её резервировать?
Технология выгрузки-загрузки данных
После определения списка скачиваемых таблиц (каждая из которых скачивается целиком) можно вообще больше ничего не делать, не писать никаких скриптов, а использовать программу Phpmyadmin, которая есть на большинстве хостингов: запускаете её, выбираете базу данных, щёлкаете ссылку "Экспорт", выбираете (удерживая клавишу Control) таблицы из списка – и скачиваете себе на компьютер файл с данными. Так все делают вначале. И мы тоже так делали. Потом надоело: во-первых, при ползании по страницам Phpmyadmin скачиваешь чуть ли не мегабайты, сравнимые с размером самой БД; во-вторых, куча лишних движений мышью и пальцами; в общем, и время тратишь, и трафик, и внимание (усилия глаз и мозга).
К тому же при копировании данных с одного удалённого хостинга (host1) на другой (host2) вообще нет необходимости скачивать их сначала к себе на компьютер. Копируете на host1 файл bdout.php, на host2 – файл bdin.php. Открываете ссылку host2/bdin.php, и видите примерно следующую картину (если закомментировать строку авторизации "require "a.inc.php"; //авторизация"):
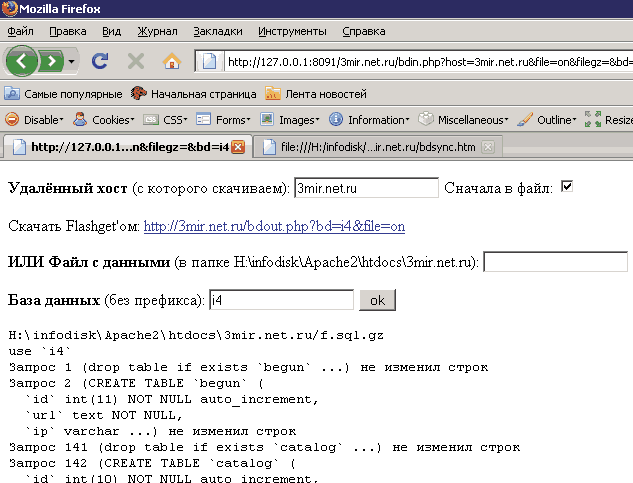
У нас в примере, правда, уже все необходимые поля заполнены и нажата кнопка "oK" – так, что виден результат загрузки данных на host2 (у нас это 127.0.0.1:8091).
Механизм взаимодействия пользователя со скриптами такой. По мере заполнения полей HTML-формы на странице формируется ссылка на удалённый host1 (с которого надо скачать данные – у нас 3mir.net.ru). При нажатии кнопки ok, аднако, вся работа javascript'а по формированию ссылки пропадает даром – потому что эту ссылку заново формирует PHP-скрипт bdin.php, разбирая параметры GET-запроса, сформированного HTML-формой и отправленного "на себя" (как видно в адресной строке браузера). А потом bdin.php пишет (в строке 66): copy("ссылка-на-хост1","файл-в-папке-хост2"), и, если команда прокатывает, начинает загрузку данных из скопированного файла в БД.
Для нормальной работы скрипта достаточно заполнить два поля: "Удалённый хост" и "База данных". Всё остальное – излишества, добавленные от страха перед сбоями (в основном, из-за плохой интернет-связи):
1) "Сначала в файл" – если отметить этот флажок, данные с удалённого хоста2 не будут направляться пользователю PHP-скриптом; скрипт выгрузит данные сначала в файл (в своей папке), а потом передаст пользователю ссылку на этот файл header'ом;
2) "Скачать Flashget'ом" – это как раз ссылка, формируемая "на лету" javascript'ом; можно скопировать эту ссылку и добавить в программу для скачивания; если при этом будет отмечен флажок "Сначала в файл", никакая плохая связь не помешает Flashget'у вытянуть с сайта файл с данными;
3) файл с данными, полученный тем или иным способом, следует поместить потом в папку, где лежит принимающий скрипт bdin.php (там указан полный путь, у нас это папка H:\infodisk\Apache2\htdocs\3mir.net.ru); если host2 с принимающим скриптом где-то далеко, файл с данными туда можно скопировать по ftp;
Тут, правда, возникает некоторая неувязка (мы уже говорили об этом): зачем копировать файл с host2 сначала к себе на компьютер, а не сразу (и быстро!) перегнать данные с host2 на host1? В нашей практике возникало два случая такой необходимости: 1) когда host1 и есть наш компьютер, и 2) когда копирование с одного хостинга на другой разнесено во времени (и какое-то время файлы с данными должны где-то храниться).
Описание скрипта, выгружающего данные (bdout.php)
Этот скрипт проще принимающего (так бывает всегда). Основная сложность в том, что он берёт многие переменные из файла configbase.php (как и все наши скрипты). На всякий случай мы перечислили эти переменные в комментарии в начале скрипта. Ещё одно неудобство – в этом скрипте нет HTML-формы для визуальных настроек, отлаживать его работу можно только с помощью адресной строки браузера. Например, если ввести туда команду {host2}/bdout.php?bd=i0Us1, скрипт выведет на экран сообщение "Unknown database 'i0Us1'".
Если всё правильно, БД существует и в ней есть таблицы, скрипт через sql-запрос "show tables" получает список таблиц выбранной БД, затем отбрасывает таблицы, название которых начинается на private и script. О private мы говорили выше, таблицы на script хранят файлы (в т.ч. php-скрипты) сайта и должны копироваться отдельно, скриптом scriptsallout.php (мы выбрали такую идеологию). Если указать в параметрах обращения к скрипту таблицу (bdout.php?bd=i4&tab=zap), будет скачиваться только одна эта таблица (если она не начинаетя на private_).
Затем запросом "show create table `{table}`" получаем структуру каждой таблицы, пишем "удалить таблицу `{table}`", "создать таблицу `{table}`", "поместить данные в таблицу `{table}`" и перечисляем в цикле, какие именно данные. То есть все копируемые нашей системой таблицы полностью удаляются (на принимающем хосте) и записываются заново.
В конце каждого sql-запроса стоит особый разделитель из нескольких символов (переменная $div), такой же разделитель должен быть в принимающем скрипте bdin.php. Ну, и в каждой строке выгружаемых данных экранируются концы строк, нули и ещё какие-то символы: $fieldval="'".addcslashes($fields[$j],"\"\'\r\n\0\t")."'"; – об этом мы подробнее писали в последней части статьи – Хостинг в Иркутске.
Все выгружаемые данные сжимаются функцией gzencode($str, 9), поэтому приходится эти данные накапливать – ведь если сжимать каждую строку таблицы, сжатие будет неэффективным, несмотря на поставленное нами число "9" (максимальное сжатие). Мы опытным путём определили число 300000 (байт), и сжимаем строку и отправляем её в поток (или в gz-файл) после достижения строкой этой длины. Ну, а в конце проверяем, была ли длина всех данных кратна 300000 :-), и если нет, сжимаем и выводим то, что осталось.
Описание скрипта, принимающего данные (bdin.php)
Самое плохое в этом скрипте – строка 12: 'require "a.inc.php"; //авторизация'. Потому что я сам до сих пор не знаю, как всё это работает. Но вы сами можете попробовать разобраться с помощью традиционной для нашей системы ссылки a.inc.php. Или просто закомментировать эту строку при использовании скрипта на своём сайте.
Самое сложное в этом скрипте – javascript, на котором строится взаимодействие пользователя со страницей (и которого многие РHP-программисты до сих пор побаиваются). Всякие onkeyup, onchange и прочие innerHTML. Зато именно благодаря этому javascript'у и HTML-форме bdin.php удобнее отлаживать в наглядном, визуальном режиме. Да и пользоваться удобнее; он с таким расчётом и делался – как звено в системе, за которое следует потянуть, чтобы вытянуть всю цепь.
Скрипт рассчитан на приём строго определённых данных (сжатых gz-компрессией и в кодировке cp1251), это не универсальный Phpmyadmin. Ну так зато он и короче Phpmyadmin'а в тысячу раз (это не гипербола). При всех известных начальных условиях сам фрагмент программы, считывающий данные из gz-файла и запихивающий их в БД занимает всего 26 строк (со строки 74 до конца файла).
Синхронизация
Синхронизация должна быть более быстрой, чем резервное копирование, информации должно скачиваться как можно меньше. Для этого нужно определить, что именно изменяется в часто изменяемых (больших – мелкие можно скачивать целиком) таблицах, и попытаться выделить для скачивания именно эту изменяемую часть.
У нас это, например, таблица объявлений на Доске объявлений «Иркутск». Каждое объявление имеет дату (штамп времени mysql). Чтобы определить интервал дат, надо задать начальную дату; она определяется на стороне «клиента» – это объявление с самой поздней датой в таблице, в которую надо добавить новые данные. Традиционным «клиентом синхронизации» для нашей Доски объявлений и Справочника иркутских предприятий является Инфодиск – веб-сервер с готовыми сайтами и базами данных, устанавливаемый на компьютеры с Windows простым копированием (описание есть на http://soft.infodisk.info/). Там при обновлении информации (скачивании новой с интернет-сайтов) задаётся параметр – начальная дата. Она определяется автоматически, но пользователь при желании может изменить её, задать другое значение через HTML-форму.
Особенность задачи по синхронизации в том, что нельзя использовать простой список таблиц БД (полученный запросом show tables); кроме исключений private и script должны быть добавлены совершенно произвольные исключения (таблицы, у которых не скачивается структура, а скачиваются только новые данные). Пока эта задача решена у нас топорным методом двух списков: "полных таблиц" и "обновляемых таблиц". Каждый из списков обрабатывается своей функцией (это делается отдельными скриптами, не описанными здесь). Вероятно, правильнее всё-таки иметь один список исключений, и, сравнивая с ним список всех таблиц, получить список "полных таблиц":
$listhard= array_diff ($tarr, $listupd); (строка 51 скрипта bdout.php)
Пока этот результат сравнения двух списков не используется в описываемой здесь системе. Но можно добавить в файл bdin.php, например, поле "Дата" и отправлять его значение на удалённый хост, а скрипт bdout.php при получении параметра "Дата" должен будет использовать список обновляемых исключений (а не скачивать все "не-private" таблицы целиком).
При "обновляемой" синхронизации возикает ещё одна сложность: мы добавляем новые записи, полученные из таблиц удалённого хоста, но мы не знаем, какие записи были там за прошедший период удалены (уничтожены). Следовательно, нужен ещё список ключей (primary key) исходной таблицы за данный период; этот список надо будет сравнить с целевой таблицей (которую обновляем) и уничтожить в целевой таблице строки с первичными ключами, отсутствующими в полученном списке. Сначала – уничтожить, а потом загрузить обновление (а не наоборот).
Для идеальной синхронизации (наиболее оптимальной и точной) лучше всего полностью протоколировать действия пользователей (и администраторов:-) сайта, изменяющие данные в БД, – делать это, например, в отдельной таблице mysql. Это можно делать вообще без участия PHP (во всяком случае, в Mysql5) – с помощью триггеров: mysql-процедур, привязанных к определённым событиям в определённой таблице. Понятно, что в этом случае триггер (точнее, целых три триггера) нужен для каждой таблицы БД (кроме самой таблицы "Протокол"), а события – это добавление, удаление и обновление записей.
К сожалению, на «виртуальных» хостингах использование триггеров Mysql пока невозможно, так как оно требует привилегии SUPER, а кто ж её даст. Может быть, только d-host (если опять заработает сервер).
© 2009, «Деловая неделя», Михаил Гутентог
Сложновато. Да и копировать таблицы целиком... Можно сделать так: Создать новую таблицу. Туда будут записываться изменения (точнее запросы, которые нужно выполнить в другой (противоположной) базе. Создать ее нужно в обеих базах. Далее, добавить триггеры к таблицам, необходимым для синхронизации. Триггеры будут записывать необходимые запросы в нашу новую таблицу. При этом можно будет проверять дополнительные условия. Процесс обмена будет сводиться к передачи запросов из нашей новой таблицы, выполнению на другой базе, при успехе стрианию переданных запросов.
29.05.2012 05:39:45